WATANABE REN wrote a new post, 時系列DFの平日のデータのみを抽出 1年 9か月前
DatetimeIndex の weekday 属性を利用してフィルタリングする。
import pandas as pd
# サンプルデータの作成
date_rng = pd.date_range(start=’2023-01-01′, end=’2023-01-31′, freq=’D’)
df = pd.DataFrame(date_r[…]
WATANABE REN wrote a new post, 任意のtimezonに変換する関数 1年 10か月前
def convert_to_timezone(dt, target_timezone):
“””
入力されたdatetimeを任意のタイムゾーンに変換する関数。
入力datetimeがタイムゾーン情報を持たない場合は、UTCとみなす。
Args:
[…]
WATANABE REN wrote a new post, 白黒テスト 1年 11か月前
ホワイトボックステスト
ホワイトボックステストは、ソフトウェアの内部構造、設計、実装に焦点を当てたテスト手法。プログラマーやテスターがコードの内部を見て、特定の入力が与えられた場合に内部動作や出力が期待どおりであるかを検証する。ホワイトボックステストは、通常、単体テストの形で実施され、プログラムの各機能を個別にテストする。コードの論理的なパスを通過すること、分岐(if/else文)、ループ(for、while文)、そして境界[…]
WATANABE REN wrote a new post, 形式手法 2年 1か月前
形式手法(Formal Methods)は[…]
WATANABE REN wrote a new post, 命令型プログラミングと宣言型プログラミングの違い 2年 2か月前
命令型プログラミング(Imperative Programming)
プロセス指向: 命令型プログラミングでは、プログラマーがコンピュータに「何をするか」お[…]
WATANABE REN wrote a new post, pytestをプログラム内で実行する方法 2年 3か月前
[…]
WATANABE REN wrote a new post, チャットツールの開発における肯定的な意見 2年 4か月前
システム開発におけるチャットツールの位置づけは非常に重要だ。以下の理由で肯定的に見るべきだ。
コミュニケーション効率化: チャットツールはリアルタイムで情報共有を可能にし、開発チームの問題解決を早める。これによりプロジェクトがスムーズに進む。
遠隔地との協力: 遠隔地のチームやクライアントと簡単にコミュニケーションできるため、地理的制約を超えた[…]
WATANABE REN wrote a new post, マイクロフロントエンド 2年 5か月前
マイクロフロントエンドアーキテクチャは、ウェブアプリケーションのフロントエンドのモノリシックな構造を小さなコンポーネントに分割し、それらを単一のページ上で組み合わせることを可能にする設計スタイル。このアーキテクチャスタイルは、バックエンドのマイクロサービスが行うのと同様に、フロントエンドの構造を分割して、より管理しやすく、スケーラブルにすることを目的としている。
1. コンポーネントの分割:
– アプリケーションのフロ[…]
WATANABE REN wrote a new post, GPT-4をAPIとして利用できるSaaS 2年 6か月前
Poe.com:[…]
WATANABE REN wrote a new post, 言語AIの性質 2年 7か月前
以下はGPT-4の特徴
膨大な情報: GPT-4は、数兆の単語から成る広範なテキ[…]
WATANABE REN wrote a new post, 課題の目的が曖昧なまま作業を行わせないための戦略 2年 8か月前
SMART原則: 課題を[…]
WATANABE REN wrote a new post, 相手の理解度を確認する方法 2年 9か月前
課題の共有を行った際の相手の理解度を確認する方法としては、以下のような手法がある。
フィードバックを求める: メンバーに課題の理解度を自己報告させることで、彼らの理解度を把握します。具体的な質問をしてみることも有効。
確認の再度求める: 一度説明した後に、メンバーにそれを自分の言葉で説明させてみると、理解度が[…]
WATANABE REN wrote a new post, リモートワーク環境で必要になるマネジメント能力 2年 10か月前
リモートワーク環境で必要になるマネジメント能力。
コミュニケーション能力: チャットやビデオ通話など、デジタルツールを用いた適切なコミュニケーションスキルが必須。また、メンバーの状況や感情を理解し、適切なフィードバ[…]
WATANABE REN wrote a new post, ChatGPTメモ 2年 11か月前
エンジニアの能力を測る質問
プログラミング言語: どの言語に精通していますか?その言語でどのようなプロジェクトに取り組んできましたか?
アルゴリズムとデータ構造: 基本的なアルゴリズムやデータ構造について説明できますか?例えば、バイナリツリーやハッシュマップなど。
ソフトウェア開発プロセス: Agile、Scrum、Waterfallなどの開発手法についてどのような経[…]
WATANABE REN wrote a new post, AIとエンジニアリングの今後について 3年前
AI(人工知能)とエンジニアリングの今後は、技術革新が加速し続けることにより、より多くの産業や日常生活に大きな影響を与えるでしょう。エンジニア的観点から見ると、以下のようなトレンドや進展が期待されます。
まず、AI技術の進歩により、機械学習モデルがより複雑で高度なタスクを達成できるようになります。これにより、自動運転車、ロボット工学、スマートシティなどの分野で大きなブレークスルーが起こる可能性があります。また、量子コンピ[…]
WATANABE REN wrote a new post, pandasのPivotについて⑤ 3年 1か月前
クロス集計
クロス集計とは、単純集計に集計を掛け合わせ、集計内容を分析する。
母集団から要素ごと部分部分で集計するので、標本数が減るためあまりにも少なくなって有効な統計量じゃなくなる可能性があるので注意。
上記を踏まえてpandasのクロス集計メソッド。
foo, bar, dull, shiny, one, two = “foo”, “bar”, “dull”, “shiny”, “one”, “two”[…] 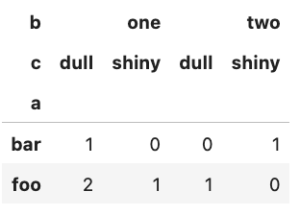
WATANABE REN wrote a new post, pandasのPivotについて④ 3年 2か月前
pivotメソッドの一般的なバージョン。
import datetime
df = pd.DataFrame(
{
“A”: [“one”, “one”, “two”, “three”] * 6,
“B”: [“A”, “B”, “C”] * 8,
“C”: [“foo”, “foo”, “foo”, “bar”, “bar”, “bar”] * 4[…] 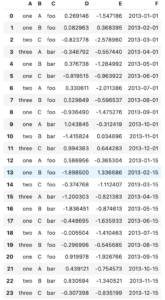
WATANABE REN wrote a new post, pandasのPivotについて③ 3年 3か月前
meltによるReshaping
unstackより柔軟性がある縦持ち方法。早めに知っておきたかった。
cheese = pd.DataFrame(
{
“first”: [“John”, “Mary”],
“last”: [“Doe”, “Bo”],
“height”: [5.5, 6.0],
“weight”: [130, 150[…] 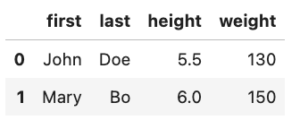
WATANABE REN wrote a new post, pandasのPivotについて② 3年 4か月前
列をMultiIndexとして格納するメソッドにstackがある。
tuples = list(zip(*[[“bar”, “bar”, “baz”, “baz”, “foo”, “foo”, “qux”, “qux”], [“one”, “two”, “one”, “two”, “one”, “two”, “one”, “two”],]))
index = pd.MultiIndex.f[…] 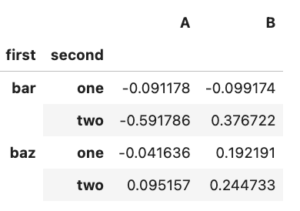
WATANABE REN wrote a new post, Pandas の pivotについて 3年 5か月前
軸ラベルを回転させてDataframeをもっと見やすくする。
Excelのピボットテーブルと同じ機能。
Dataframeに.pivotメソッドが用意されている。
def unpivot(frame):
“””
渡されたDFのIndexとColumnsを値とともに列方向に並べる。
“””
N, K = frame.shape
data = {
“value[…] 